Pitch Coach AI
Real-time AI sales-coaching platform live across a 350+ location network. Half-cascade voice pipeline with deterministic per-persona voices and async rubric grading.
2026
- 20 Architecture Decision Records
- 199+ pytest tests with rubric calibration validation
- Dual-rubric scoring (ISR 90-pt / OSR 100-pt)
- Half-cascade voice pipeline with deterministic per-persona voice IDs

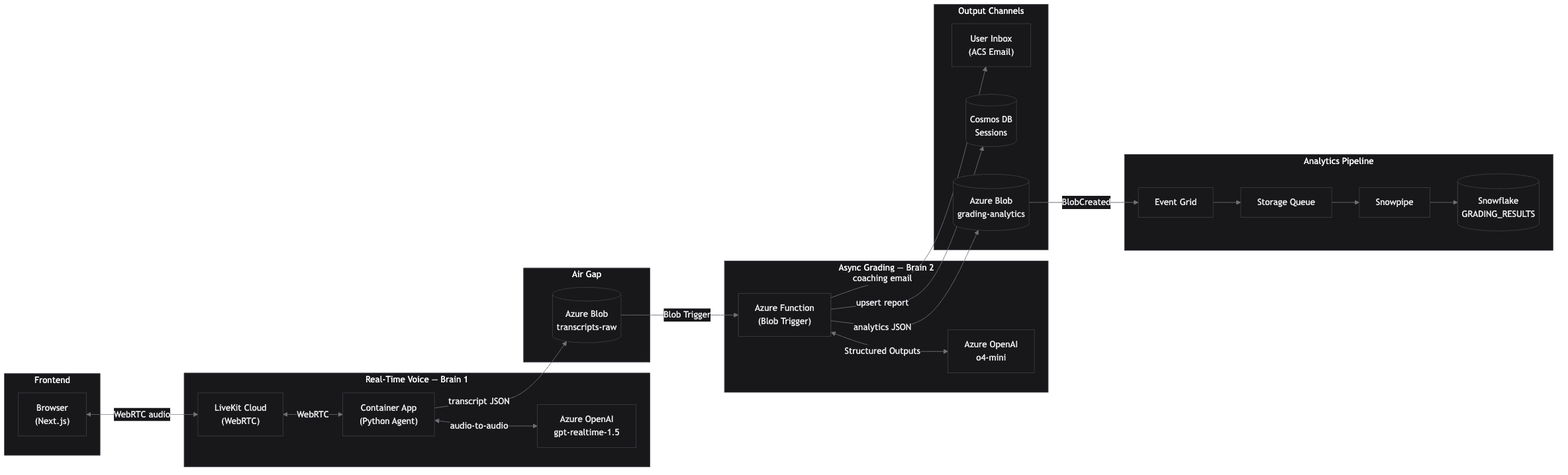
System Architecture
The Problem
Sales reps need realistic practice against varied buyer personas, but voice gender drift inside gpt-realtime's audio synthesis layer made personas wobble mid-conversation, and rubric grading takes 5-15 seconds, which cannot fit inside the 1000ms latency budget.
Approach
Half-cascade Brain 1 plus async Brain 2. gpt-realtime emits text only over LiveKit WebRTC; Azure DragonHD TTS synthesizes audio with a deterministic per-persona voice ID. Brain 2 (o4-mini + Azure Functions) handles rubric grading out of band via Azure Blob events.
Architecture
Half-cascade fixes voice gender drift by construction (ADR-020): each persona maps to a fixed DragonHD voice ID that the model never overrides because the model emits no audio. Azure Speech is authed via Microsoft Entra managed identity, so no plaintext Speech key lives anywhere. After a session ends, transcript JSON triggers Brain 2 via Blob event; the grader scores ISR (90-pt) or OSR (100-pt) rubrics using Structured Outputs and emails coaching reports via Azure Communication Services.
Results
- 20 Architecture Decision Records
- 199+ pytest tests with rubric calibration validation
- Dual-rubric scoring (ISR 90-pt / OSR 100-pt)
- Half-cascade voice pipeline with deterministic per-persona voice IDs
- TTS TTFB p95 ~316ms measured against the 1000ms glass-to-glass HARD gate
- Snowpipe to Snowflake analytics pipeline
Lessons Learned
When latency budgets fight intelligence budgets, split the system. Event-driven coordination between two specialized loops is the right shape. The same lesson applies one level deeper: when a single model owns both intent and synthesis, voice traits can drift in ways no config knob fixes. Half-cascade puts each concern in its own component.