Hive: Multi-Agent Infrastructure
Self-hosted multi-agent infrastructure with a 6-layer defense-in-depth security model, per-agent Docker sandboxing, and zero public network ports.
2026
- 25 Architecture Decision Records
- Multiple phases shipped with additional phases in progress
- 6-layer security model from network to supply chain
- Modular domain teams with zero public ports
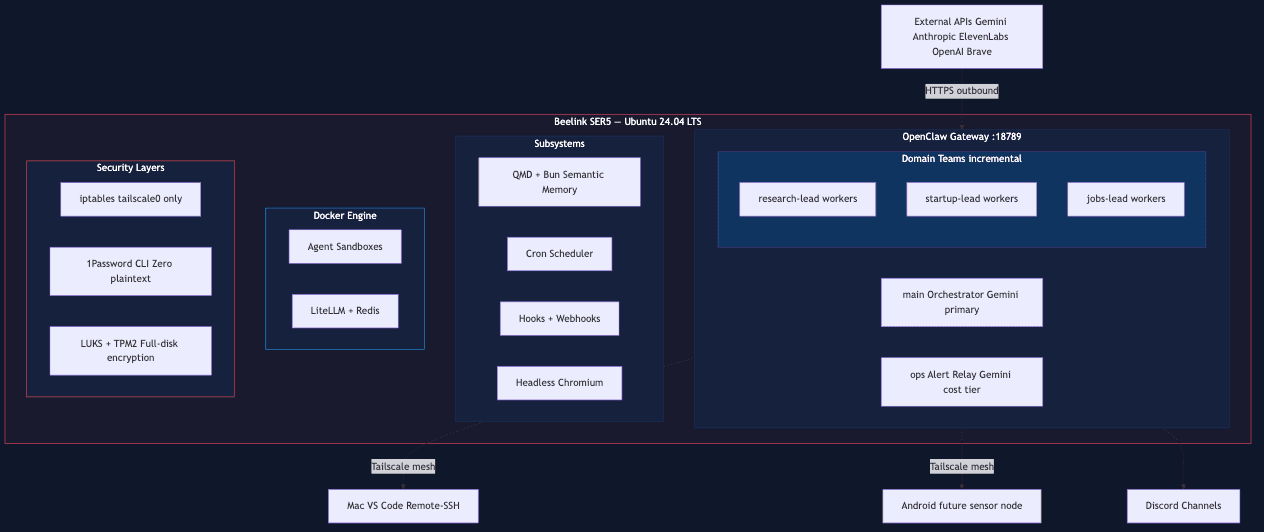
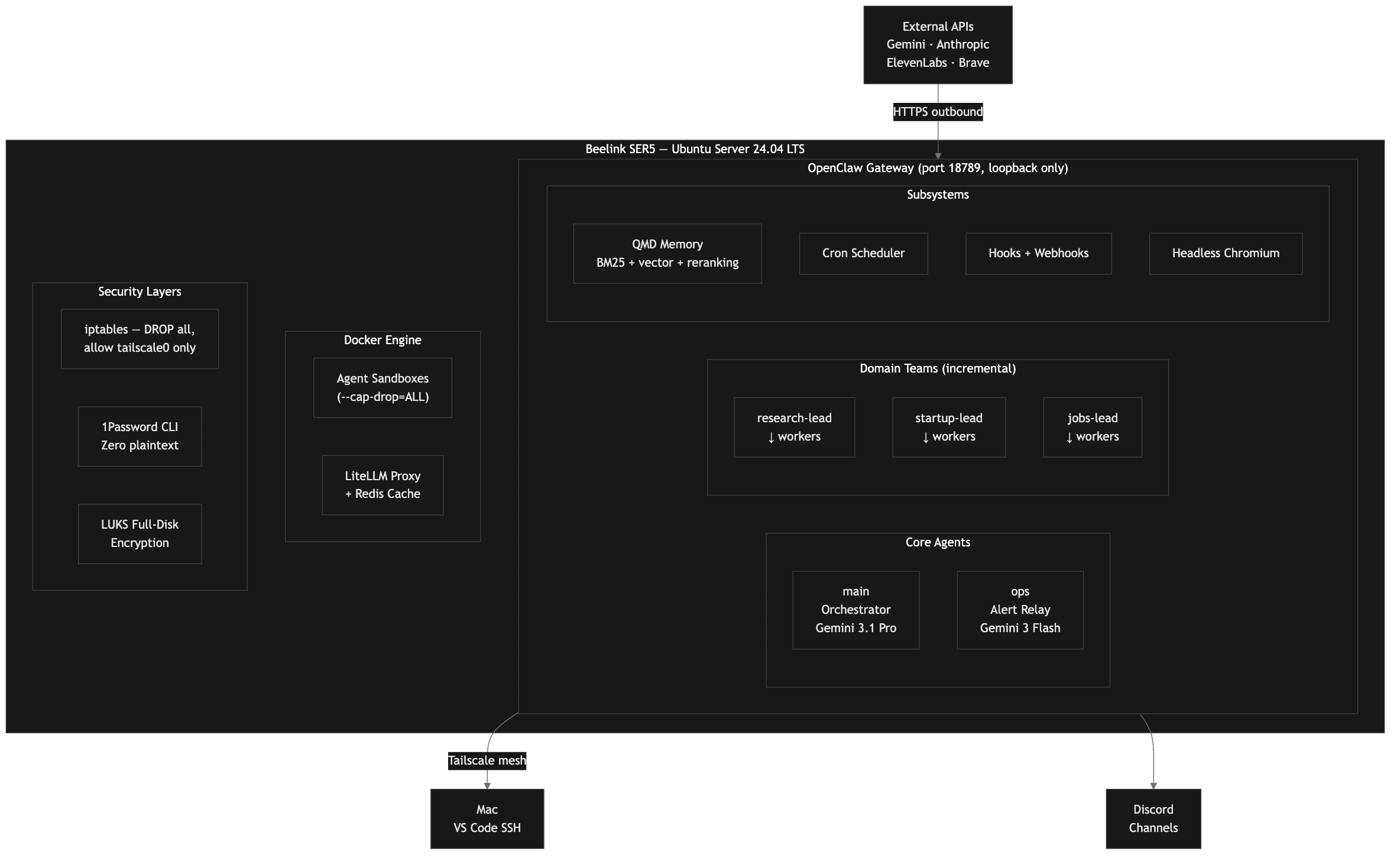
System Architecture
The Problem
Cloud AI agent platforms are expensive, opaque, and vendor-locked. Self-hosting a reliable one means owning security, cost governance, memory recall, and uptime yourself, from scratch.
Approach
A defense-in-depth, OpenClaw-native architecture: 6 security layers, modular domain teams with depth-2 agent nesting, and per-agent Docker sandboxing with dropped capabilities, deployed on a single self-hosted node. Per-agent model tiering (ADR-024) enforces a hard budget ceiling across all LLM calls.
Architecture
OpenClaw Gateway manages agent lifecycle with depth-2 nesting (orchestrator, domain leads, workers). LiteLLM proxy provides multi-provider routing with hard budget caps and three-tier fallback (Google to OpenAI to Anthropic). QMD hybrid search (BM25 + vector + MMR) plus the OpenClaw Active Memory plugin (ADR-025) handle local semantic memory and pre-reply recall. Tailscale mesh gives zero public ports. 1Password CLI injects secrets at runtime via tmpfs. Chef Antoine integrates the Kroger Cart API via host cron pre-fetch (ADR-023) without breaking the agent's Docker --network=none isolation.
Results
- 25 Architecture Decision Records
- Multiple phases shipped with additional phases in progress
- 6-layer security model from network to supply chain
- Modular domain teams with zero public ports
- LiteLLM cost governance: hard budget ceiling enforced via per-agent model tiering with three-tier provider failover (Google, OpenAI, Anthropic)
- Per-agent model tiering (Pro for creative work, Flash for orchestration, Haiku 4.5 as fallback) with a hard budget cap enforced at the LiteLLM proxy layer
Lessons Learned
Defense-in-depth security on a self-hosted node can match cloud-hosted alternatives when each layer is implemented independently. Cost governance is a first-class architectural concern; treating it as such from the start means a hard budget ceiling enforced at the proxy layer, not a manual check after the bill arrives. Memory recall scales further with server-side RAG than with summary stuffing, and OpenClaw's bundled Active Memory plugin handles it without local embedding infrastructure.